date: 2024-07-03
title: "Chain-of-Thought Reasoning Without Prompting"
status: DONE
author:
- AllenYGY
tags:
- CoT
- ReadPaper
- DeepLearning
- CoT-Decoding
publish: TrueChain-of-Thought Reasoning Without Prompting
这篇文章通过优化解码方法,提出了CoT-Decoding, 提高回答的准确性
CoT-Decoding 类似做选择题时的排除法
- 当解题人认为选项之间差距不大的时候,难以决策,或者说决策的准确性会下降
- 对应到解码就是,不同 token 的概率差距不大的时候
- 而当解题人认为选项答案差距较大时,决策的准确性会提高
- 对应到解码就是,不同 token 的概率差距较大的时候
Greedy Decoding
传统的解码方法是 Greedy decoding
贪婪解码(Greedy Decoding)是一种简单的序列生成方法,通常用于自然语言处理中的文本生成任务。在这种方法中,每一步都选择具有最高概率的下一个词作为输出,直到生成结束符或达到预定的输出长度。
具体过程如下:
- 从模型生成的概率分布中选择概率最高的词作为当前步的输出。
- 将这个词作为输入,继续生成下一个词。
- 重复上述步骤,直到生成完整的序列。
贪婪解码的优点是实现简单,速度快,因为它只需在每一步选择一个最高概率的词。然而,这种方法有一个明显的缺点,即它可能会错过全局最优的序列。由于每一步都只选择局部最优的词,贪婪解码可能会导致生成的文本质量较低,缺乏连贯性和多样性。
例如,在给定一个语言模型预测下一个词的任务中,如果模型在某一步预测的概率分布为:
- "The":0.5
- "A":0.3
- "An":0.2
贪婪解码会选择概率最高的词 "The" 作为输出,然后继续这个过程,选择下一个词,直到生成完整的句子。
Chain-of-Thought (CoT) Decoding
CoT-Decoding
The formula represents the confidence score
Where:
Here,
The model’s overall confidence in decoding the final answer is approximated by averaging these probability differences for all relevant answer tokens
- 在生成第一个 token 时,在 n 个 token 中选择前 k个 token
- 现在每个 token 都对应了该推理路径的起点,之后模型对每条路径都采用 Greedy Decoding 的方式生成后续的 token
- 在生成 token 的同时,将该时刻生成的 n 个 token 里 softmax 排名最高的两个 token 概率相减,累加到该路径的置信度中
- 最后选择置信度最高的路径作为最终的推理路径
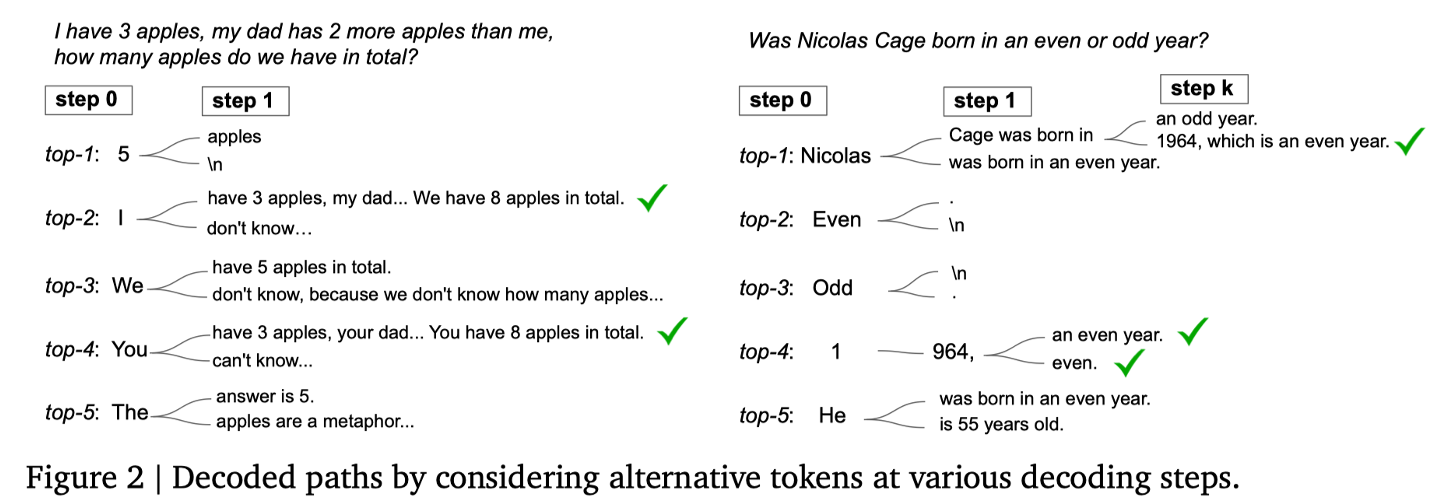
- 当解题人认为选项之间差距不大的时候,难以决策,或者说决策的准确率会下降
- 对应到解码就是,不同 token 的概率差距不大的时候
- 而当解题人认为选项答案差距较大时,决策的准确性会提高
- 对应到解码就是,不同 token 的概率差距较大的时候
Aggregation of Decoding Paths
这个公式表示对答案
其中:
这个公式表示将所有解码路径中对答案
This formula represents the calculation method for the overall confidence degree
Where:
This formula indicates that the overall confidence degree of answer
Experiments
-
CoT-Decoding Effectively Elicits Reasoning from Language Models
CoT-Decoding 能有效地从语言模型引导出推理路径- 首先是把 CoT-Decoding 与其他解码方法进行对比
- 然后是测试 CoT-Decoding 在不同参数量的同一个模型影响
- 以及 k 值的选择对结果的影响
-
CoT-Decoding Enables a Better Understanding of Model's Intrinsic Reasoning Abilities
CoT-Decoding 能更好地揭示模型的内在推理能力- 测试 CoT-Decoding 在不同推理任务上的表现
- 以及展示模型本身的推理能力不足
-
Combining CoT-decoding with CoT-Prompting
将 CoT-Decoding 与 CoT-Prompting 效果更好
Effectively Elicits Reasoning from Language Models
CoT-decoding is the only decoding strategy that effectively improves language model reasoning
这个实验采用了不同的采样和解码方法对Mistral-7B这个预训练模型进行测试
采样方法包括
解码方法包括

作者认为只有 CoT-decoding 方法可以有效地引导模型进行推理。
CoT-decoding effectively elicits reasoning across language models
在这个实验中,作者针对不同的模型包括 Mistral-7B、PaLM-2 和 Gemma,分别采用Greedy Decoding 和 Cot Decoding 进行测试。
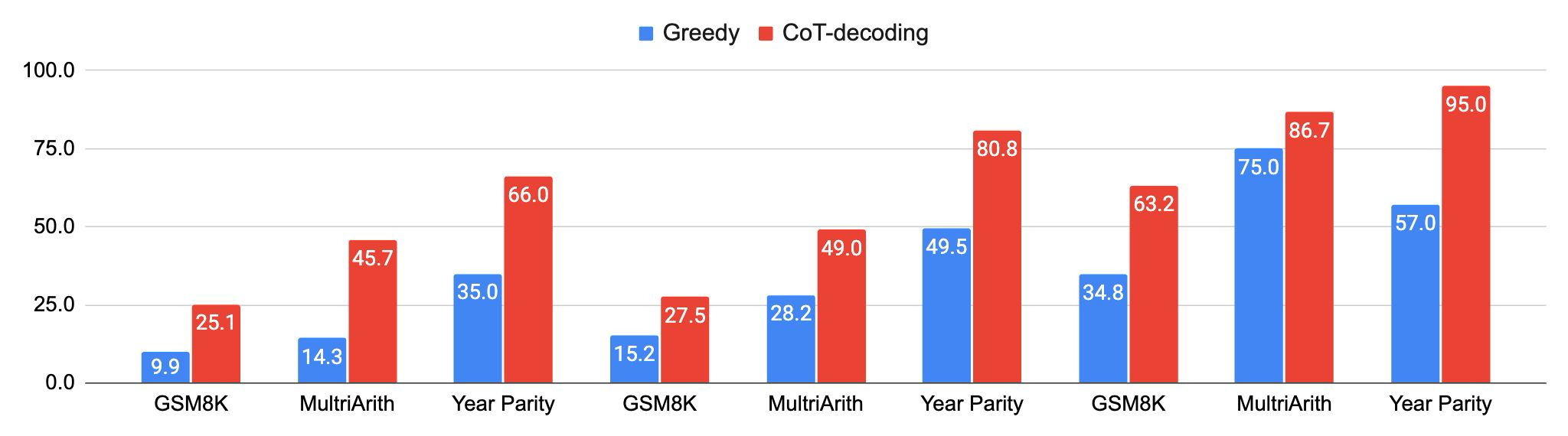
针对不同的模型,采用 CoT-Decoding 方法,都能提高模型的准确性
CoT-Decoding elicits reasoning across model scales
在这个实验中,作者对GSM8K和Year Parity两个测试集
使用不同参数的同一个模型PaLM-2进行测试
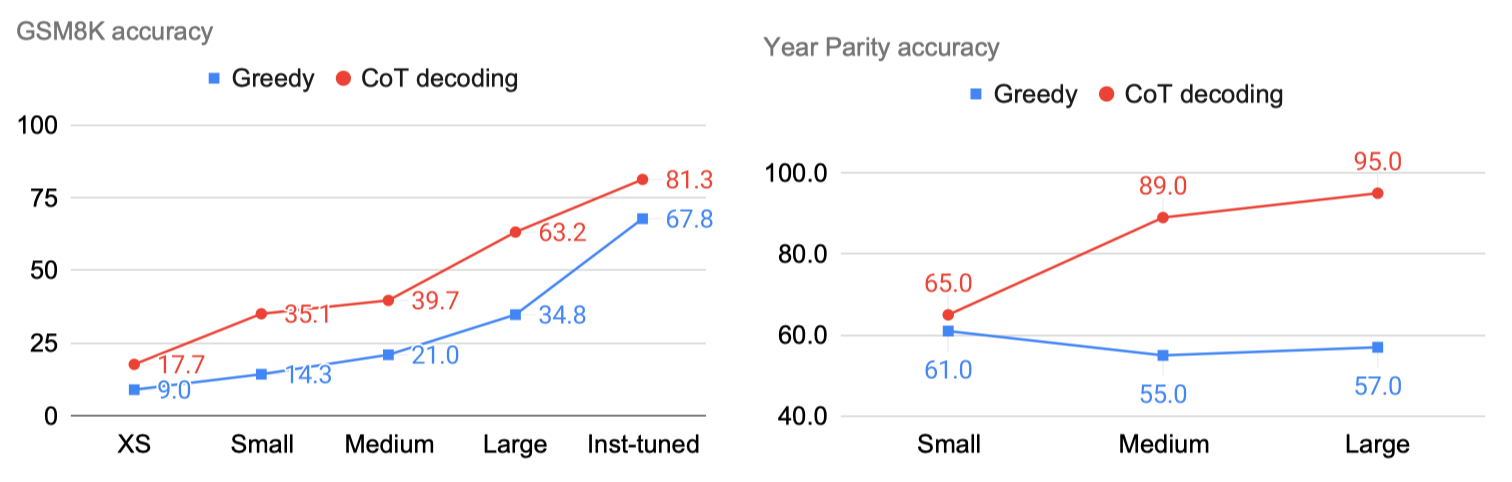
CoT-decoding reliably improves reasoning performance across model scales (PaLM-2), even when the task does not naturally improve by scaling up only (e.g., year parity).
- On GSM8K, CoT Decoding consistently yields +10-30% absolute accuracy gains.
- On year parity, when using greedy decoding, the model's performance remains flat even after scaling up model sizes.
CoT-Decoding 在不同参数大小上的模型都能表现出甚至超过下一个参数大小模型的效果
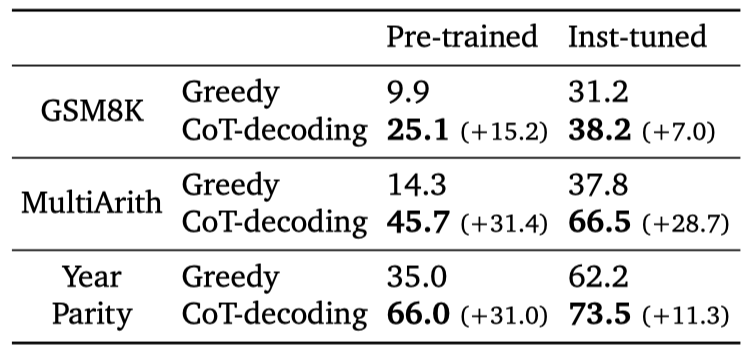
CoT-decoding partially closes the reasoning gap between pre-trained and instruction-tuned models, without using any supervised data.
在下图的 Large size 和 Instruction-tuned 的两个模型测试结果上看,两者的准确率相差不大
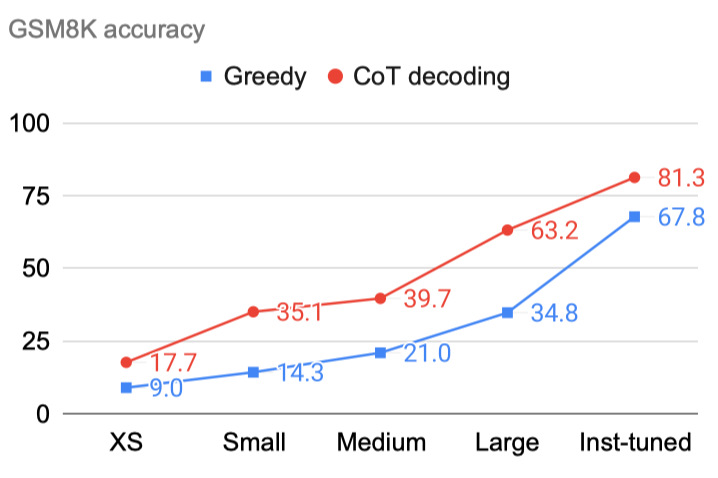
- 作者还认为,CoT-Decoding 方法可以部分地缩小预训练和指导调整模型之间的推理差距,而不需要使用任何监督数据。
更有趣的是,CoT-Decoding 可以优化 Instruction-tuned model
Choice Of K
因为 CoT-Decoding 最后还是得从模型中给出的 K 条路径里选择一条推理路径
所以 K 的选择会影响最终的结果
在这个实验里,作者对PaLM-2 model 进行不同 K 值的测试
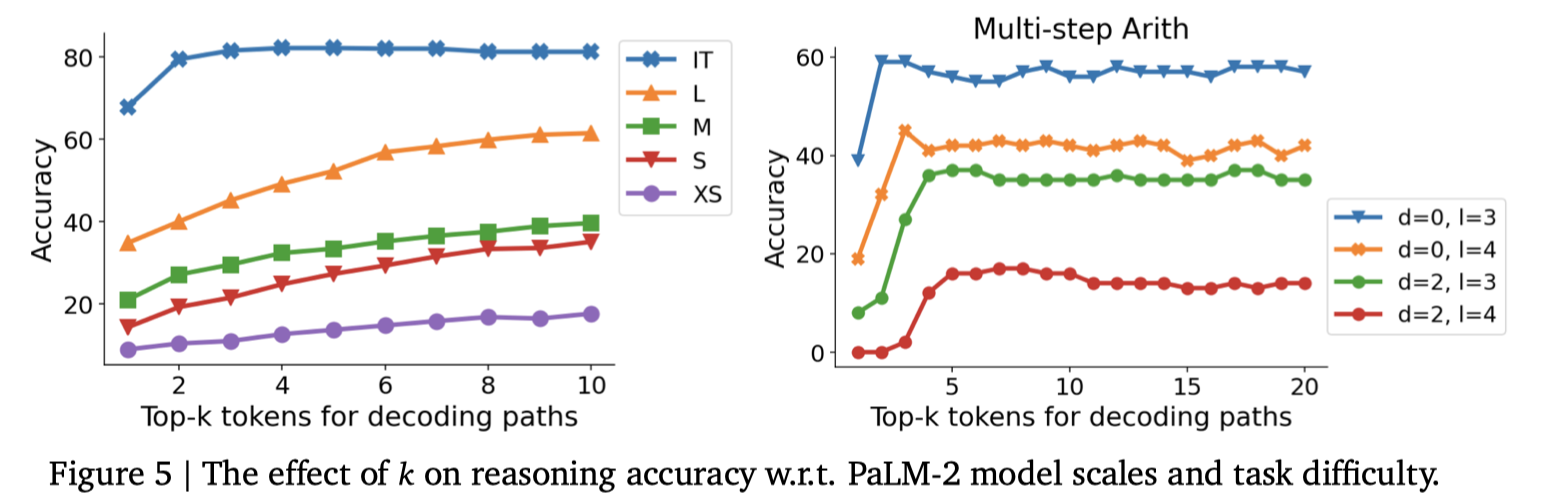
Overall we found that higher values of K typically result in improved model performance, suggesting that in many cases, the correct CoT paths may indeed exist but are often ranked lower during model's decoding.
For instruction-tuned models, the effect of 𝑘 is less significant, indicating that the process of instruction-tuning effectively brings forth the majority of CoT-paths to the first few decoding paths.
总体上看,较高的 K 值通常会导致模型性能的提高,这表明在许多情况下,正确的 CoT 路径可能确实存在,但通常在模型的贪心解码过程中排名较低。
对于指令微调的模型,K的影响较小,这表明指令调整的过程有效地将大多数 CoT 路径提到了前几个解码路径中。
Enables a Better Understanding of Model's Intrinsic Reasoning Abilities
作者认为 CoT-Decoding 能更好地揭露模型的内在推理能力
在这个实验里使用 CoT-Decoding,尝试了常见的几个推理任务
-
Coin Flip Task(抛硬币任务):
- 描述:这个任务来自Wei等人的研究(2022年)。在这个任务中,模型需要模拟多轮抛硬币的过程,并推断最终的结果。
- 难度:任务难度通过潜在抛硬币轮次(2轮、3轮、4轮)来调整。每一轮抛硬币的结果(正面或反面)会影响最终的推理过程。
-
Web of Lies Task(谎言之网任务):
- 描述:这个任务来自Big-Bench-Hard基准测试,由Suzgun等人(2022年)设计。在这个任务中,模型需要解析包含若干真假声明的语句集合,并确定哪些语句是真实的,哪些是虚假的。
- 难度:任务难度通过声明的数量(3个、4个、5个)来调整。随着声明数量的增加,推理的复杂性也随之增加。
-
Multi-step Arithmetic Task(多步骤算术任务):
- 描述:这个任务同样来自Big-Bench-Hard基准测试。在这个任务中,模型需要解决包含多个步骤的算术问题。这些问题可能涉及加法、减法、乘法、除法等基本算术运算,需要模型逐步推理出最终答案。
- 难度:任务难度通过问题的深度(𝑑)和长度(𝑙)来调整。深度表示问题包含的步骤数量,长度表示每一步涉及的操作复杂性。随着深度和长度的增加,任务的复杂性也随之增加。

- We also looked at the model's top-K decoding paths, and found that models can generate the correct CoT paths when the solution involves at most 1 or 2 step knowledge manipulation, and the model starts to struggle with generating the correct CoT-paths when the steps become 3 or more.
- This mirrors the finding in (McCoy et al., 2023), where the authors show language models are highly influenced by the distribution they have been trained on.
当解决方案涉及最多1或2步知识操作时,模型可以生成正确的 CoT 路径,但当步骤变为3或更多时,模型开始难以生成正确的 CoT 路径。作者认为这表明模型在推理方面的局限性。
作者也认为这与 (McCoy et al., 2023) 的研究结果一致,他们表明语言模型受到它们训练的分布的影响。
- On Coin-Flip and Web-of-Lies, we observe that the model can generate CoT paths that simulate the process step-by-step, but it can easily lose track of the states, especially when the task complexity increases.
- On Multi-step Arithmetic, we observe that the model tends to perform calculations from left to right in the CoT-decoding paths, rather than following the correct mathematical order.
在 Coin-Flip 和 Web-of-Lies 任务中,我们观察到模型可以生成逐步模拟过程的 CoT 路径,但当任务复杂度增加时,模型很容易失去状态。
在 Multi-step Arithmetic 任务中,我们观察到模型倾向于在 CoT-decoding 路径中从左到右进行计算,而不是按照正确的数学顺序进行计算。
总的来说,就是 CoT-Decoding 可以从模型里选到比较合理的推理路径,但没办法无中生有直接生成正确的推理路径
Combining CoT-decoding with CoT-Prompting
最后作者尝试把CoT-Decoding 和 CoT-Prompting 结合,发现效果会更好
CoT-Decoding maintains a strong performance compared to self-consistency (Wang et al., 2023a) when both are combined with CoT-prompts.
CoTCoT-Decoding 与 CoT-Prompting 结合后,与 self-consistency 方法相比,性能仍然很强。

Since self-consistency aggregates over multiple paths, we also show the performance based on our path aggregation algorithm, which significantly improves the model's reasoning at a similar cost.
由于 self-consistency 聚合了多个路径,我们还展示了基于我们的路径聚合算法的性能,在成本差不多的情况下,模型的推理能力显著提高。